With the rapid advancement of artificial intelligence and large language models, more and more companies and developers are eager to integrate language models into their own chatbot systems (LLM Chatbot). This article aims to guide readers through deploying a high-performance LLM chatbot in a Kubernetes environment using Nvidia GPU, covering everything from essential installation and tools to detailed deployment steps.
Table of Contents
Environment
We will use the following virtual machine (VM) configuration as the foundation for deployment:
- CPU: AMD Epyc 7413 16-core
- RAM: 16GB
- GPU: Tesla P4 8GB
- OS: Ubuntu 22.04
- Kubernetes CRI: containerd
Providing Nvidia GPU in Kubernetes
Install Nvidia GPU Driver
On the Ubuntu system, you can install Nvidia's proprietary drivers via the apt package manager. First, run the following command to search for available Nvidia driver versions:
apt search nvidia-driverThis tutorial will demonstrate installation using the Nvidia driver version 525:
sudo apt install nvidia-driver-525-serverAfter installation completes, you can verify the driver has been successfully installed by running the following command:
sudo dkms status
lsmod | grep nvidiaThe successful installation output will be:
nvidia-srv/525.147.05, 5.15.0-97-generic, x86_64: installed
nvidia_uvm 1363968 2
nvidia_drm 69632 0
nvidia_modeset 1241088 1 nvidia_drm
nvidia 56365056 218 nvidia_uvm,nvidia_modesetInstall Nvidia Container Toolkit
Nvidia Container Toolkit enables containers to directly access GPU resources. Install this toolkit using the following command:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkitAfter installation, configure containerd to use the Nvidia container runtime:
sudo nvidia-ctk runtime configure --runtime=containerdThis operation will modify /etc/containerd/config.toml Configure the file as follows to enable GPU support:
version = 2
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
[plugins."io.containerd.grpc.v1.cri".containerd]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"Install Nvidia Device Plugin
Use Helm to install the Nvidia device plugin so Kubernetes can detect and allocate GPU resources:
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace nvidia-device-plugin \
--create-namespace \
--version 0.14.4The detailed values file can be found atThis one obtained, and by specifying the appropriate nodeSelector, you can ensure the device plugin is installed only on nodes with GPU hardware.
Use Nvidia GPU in Pod
To make the Pod use Nvidia GPU, you need to add the following configuration in the Kubernetes YAML file:
spec:
containers:
resources:
limits:
nvidia.com/gpu: 1Deploy LLM Chatbot
Using ollama and open-webui as deployment options for LLM Chatbot, these tools have already provided Kubernetes-compatible YAML files and Helm Charts to simplify the deployment process.
The following are the steps for deploying using Kustomize:
git clone https://github.com/open-webui/open-webui.git
cd open-webui
kubectl apply -k kubernetes/manifestAfter completion, you will see two running pods under the open-webui namespace. You can access the Web UI via Ingress or NodePort, with the default port set to 8080.
kubectl get pods -n open-webui
NAME READY STATUS RESTARTS AGE
ollama-0 1/1 Running 0 3d3h
open-webui-deployment-9d6ff55b-9fq7r 1/1 Running 0 4d19h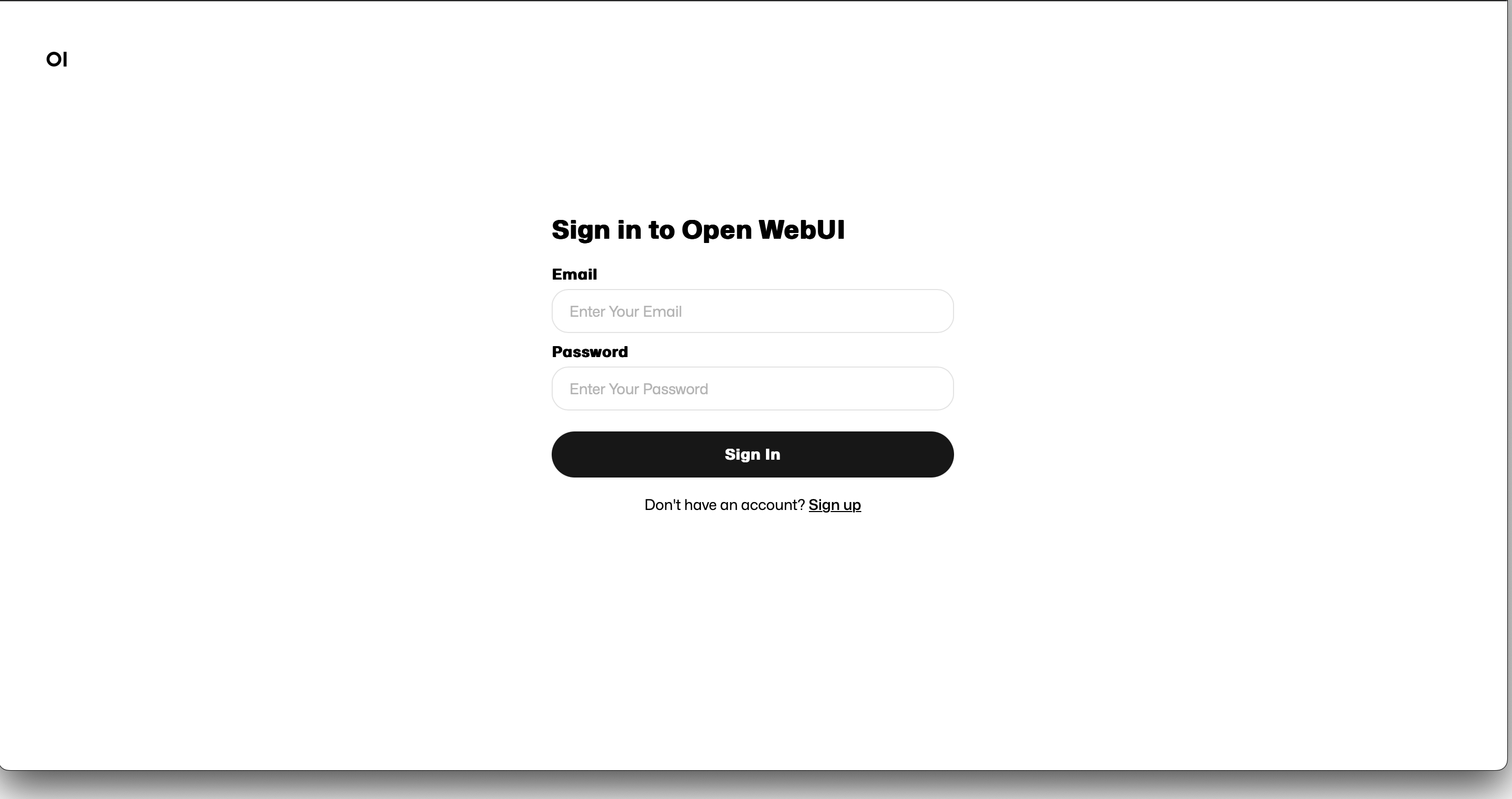
The default will automatically launch a new user registration page. After registration, you can log in using the provided username and password, and will see an interface remarkably similar to ChatGPT:

You can download an LLM model onto ollama from the configuration:
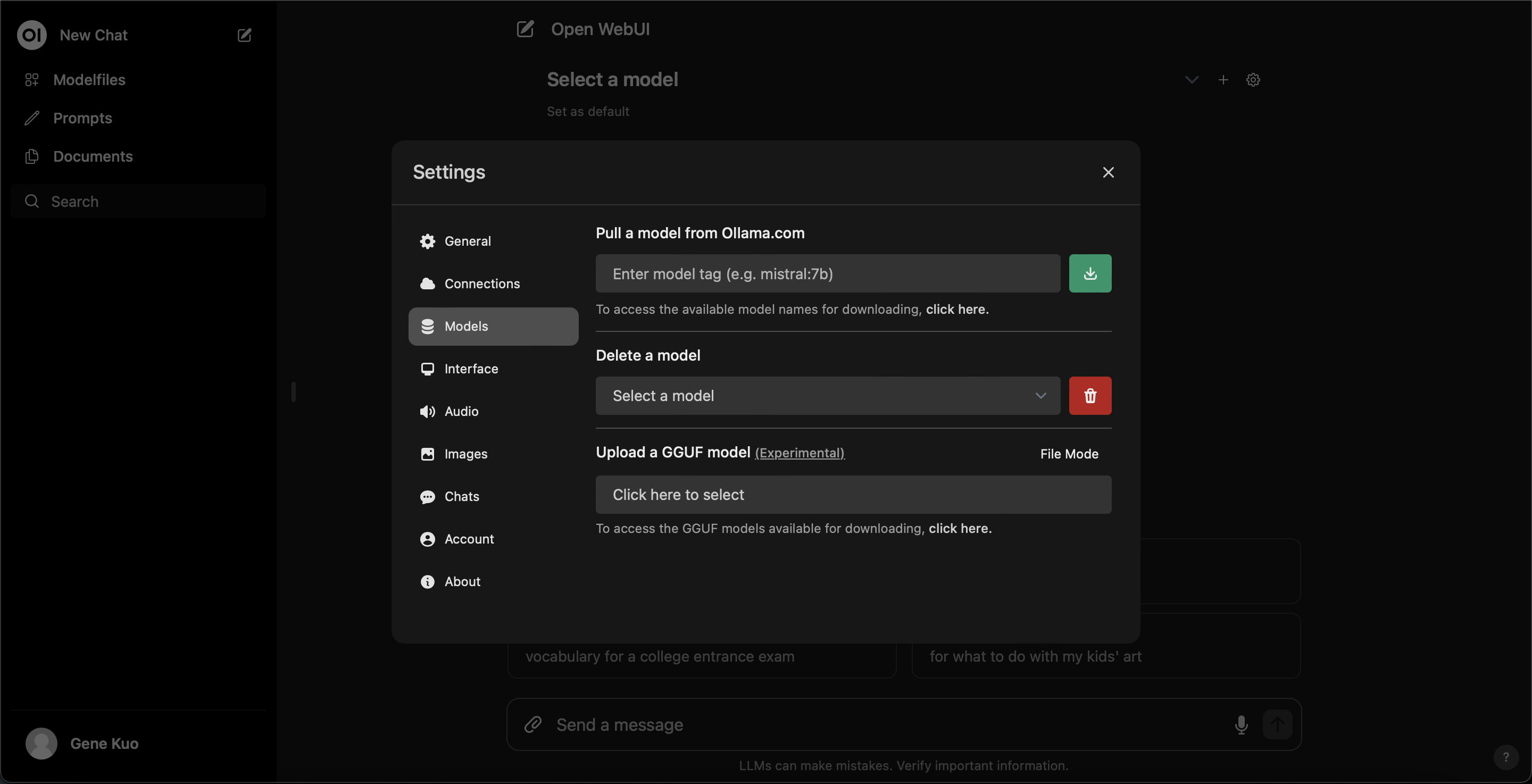
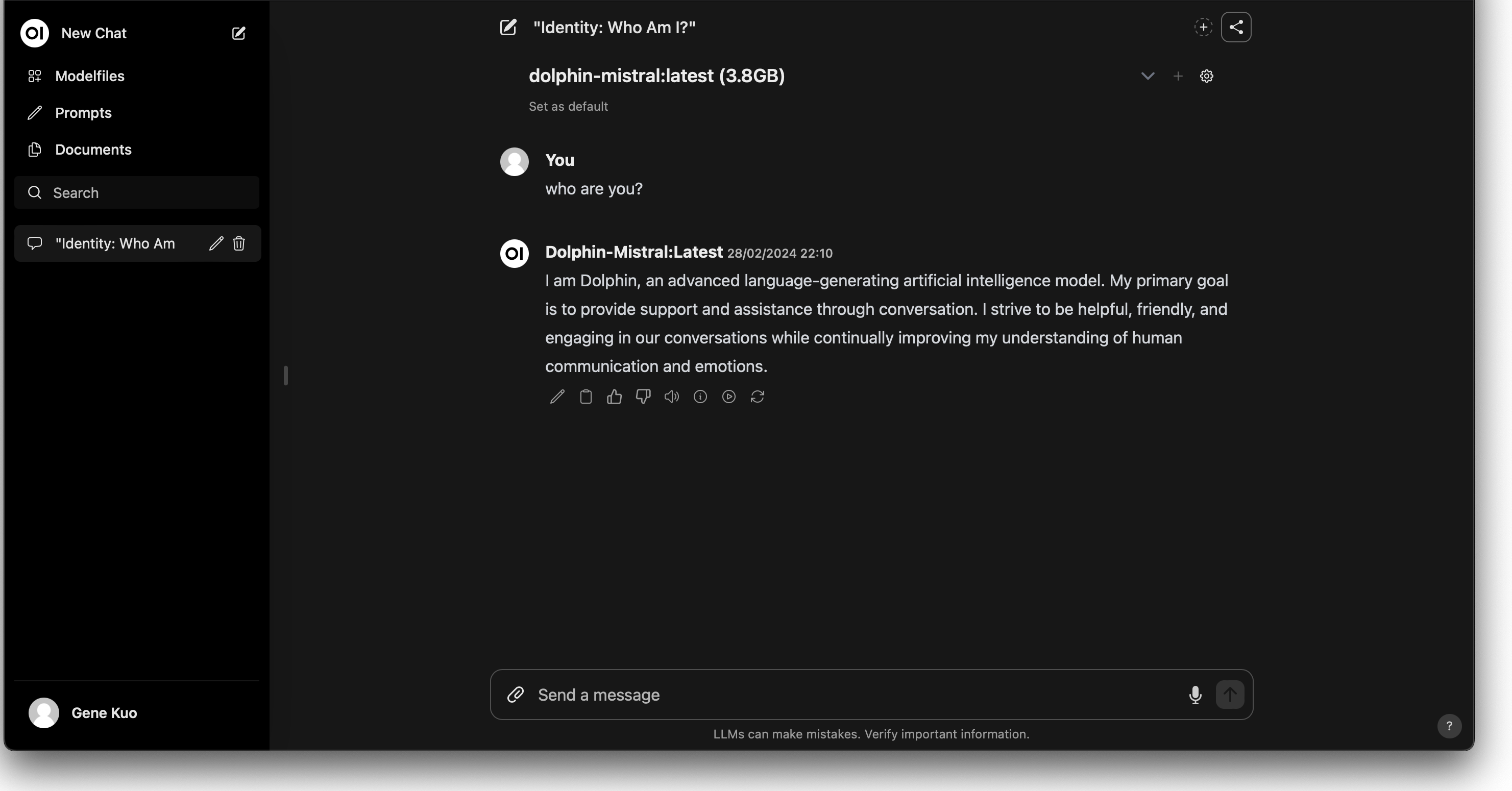
After downloading, select the desired model to start chatting with the chatbot:
Summary
Through the steps above, we have successfully deployed Nvidia GPU support in the Kubernetes environment and established a fully functional LLM Chatbot website. This not only deepened our understanding of Kubernetes and Nvidia GPU deployment, but also provided practical reference for building high-performance computing applications and interactive AI services.