AI技術の急速な発展に伴い、自社システムに大規模言語モデル(LLM)チャットボットを統合したいと考える企業や開発者が増えています。本記事では、Kubernetes環境でNvidia GPUを使用して高性能なLLMチャットボットをデプロイする方法について、必要なドライバやツールのインストールから具体的なデプロイ手順まで、順を追って解説します。
目次
環境
以下の仮想マシン(VM)構成をベースにデプロイを進めていきます。
- CPU: AMD Epyc 7413 16コア
- RAM: 16GB
- GPU: Tesla P4 8GB
- OS: Ubuntu 22.04
- Kubernetes CRI: containerd
KubernetesでのNvidia GPUの提供
Nvidiaドライバのインストール
Ubuntuシステムでは、aptパッケージマネージャーを使用してNvidiaのプロプライエタリなドライバをインストールできます。まず、以下のコマンドを使用して、利用可能なNvidiaドライバのバージョンを検索します。
apt search nvidia-driverこのチュートリアルでは、Nvidiaドライバのバージョン525を例としてインストールを行います。
sudo apt install nvidia-driver-525-serverインストール完了後、以下のコマンドでドライバが正常にインストールされたことを確認できます。
sudo dkms status
lsmod | grep nvidiaインストールに成功した場合の出力は以下のようになります。
nvidia-srv/525.147.05, 5.15.0-97-generic, x86_64: installed
nvidia_uvm 1363968 2
nvidia_drm 69632 0
nvidia_modeset 1241088 1 nvidia_drm
nvidia 56365056 218 nvidia_uvm,nvidia_modesetNvidia Container Toolkitのインストール
Nvidia Container Toolkitを使用すると、コンテナからGPUに直接アクセスできるようになります。このツールキットのインストールは、以下のコマンドで行います。
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkitインストール後、Nvidiaコンテナランタイムを使用するようにcontainerdを設定します。
sudo nvidia-ctk runtime configure --runtime=containerdこの操作により、 /etc/containerd/config.toml 設定ファイルはNvidia GPUをサポートするために以下のように変更されます:
version = 2
[plugins]
[plugins."io.containerd.grpc.v1.cri"]
[plugins."io.containerd.grpc.v1.cri".containerd]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
privileged_without_host_devices = false
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"Nvidia Device Pluginのインストール
KubernetesがGPUリソースを識別して割り当てられるように、Helmを使用してNvidia device pluginをインストールします。
helm repo add nvdp https://nvidia.github.io/k8s-device-plugin
helm repo update
helm upgrade -i nvdp nvdp/nvidia-device-plugin \
--namespace nvidia-device-plugin \
--create-namespace \
--version 0.14.4詳細な設定のvaluesファイルはこちらから取得にあります。適切な nodeSelectorを設定することで、Nvidia device pluginがGPUを搭載したノードにのみインストールされるようになります。
PodでのNvidia GPUの使用
PodでNvidia GPUを使用するには、Kubernetesのyamlファイルに以下の設定を追加する必要があります。
spec:
containers:
resources:
limits:
nvidia.com/gpu: 1LLMチャットボットのデプロイ
LLMチャットボットのデプロイ手法としてollamaとopen-webuiを採用します。これらのツールは、デプロイプロセスを簡素化するために、Kubernetes用のyamlファイルやHelmチャートを既に提供しています。
以下は、Kustomizeを利用したデプロイ手順です。
git clone https://github.com/open-webui/open-webui.git
cd open-webui
kubectl apply -k kubernetes/manifest完了すると、open-webui名前空間で2つの実行中のPodを確認できます。IngressまたはNodePortを介してWeb UIにアクセスでき、デフォルトのポート番号は8080です。
kubectl get pods -n open-webui
NAME READY STATUS RESTARTS AGE
ollama-0 1/1 Running 0 3d3h
open-webui-deployment-9d6ff55b-9fq7r 1/1 Running 0 4d19h
デフォルトでは新規ユーザー登録が有効になっています。登録後、設定したアカウント名とパスワードでログインすると、ChatGPTに非常によく似たインターフェースが表示されます。

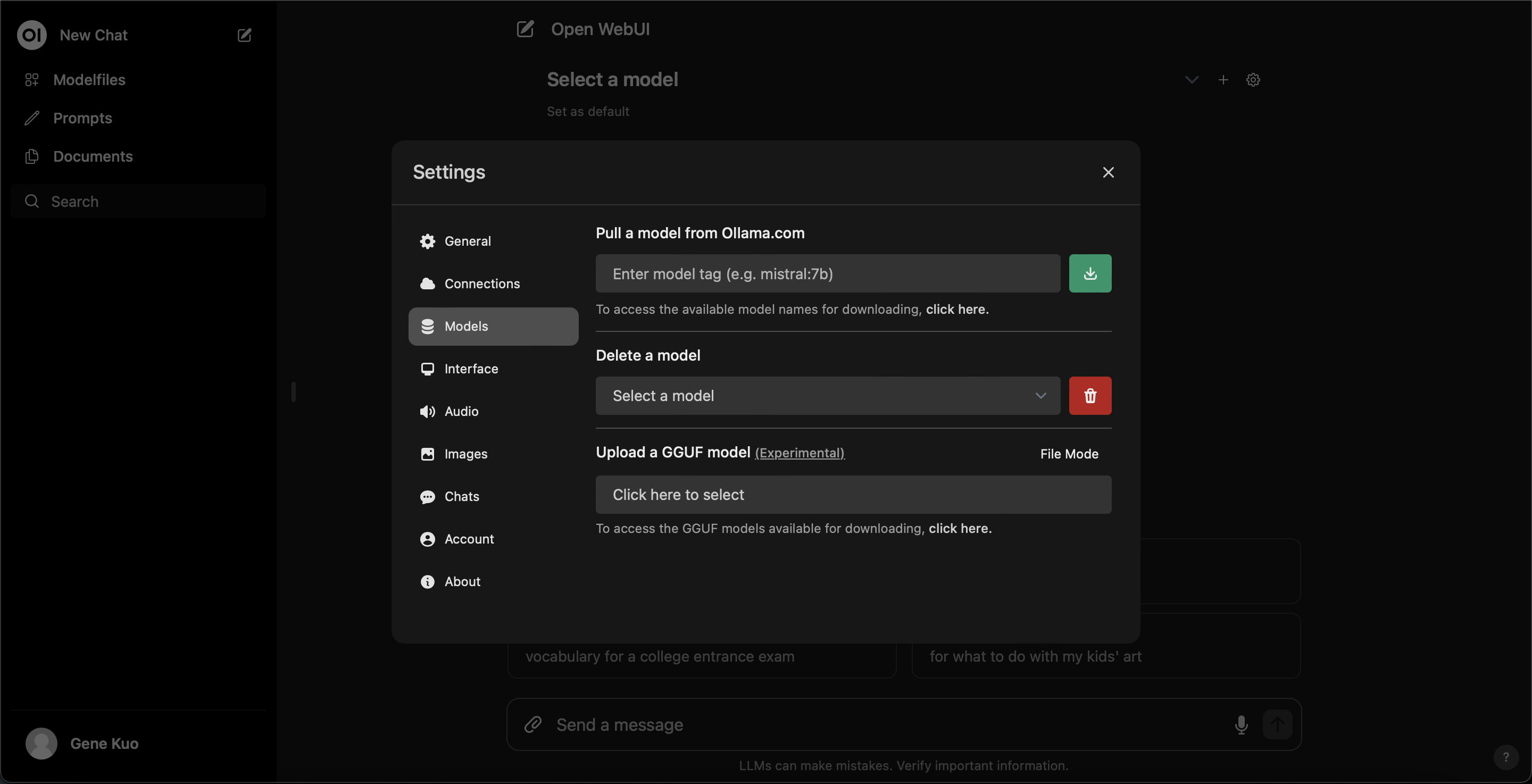
設定からollama上のLLMモデルをダウンロードできます。
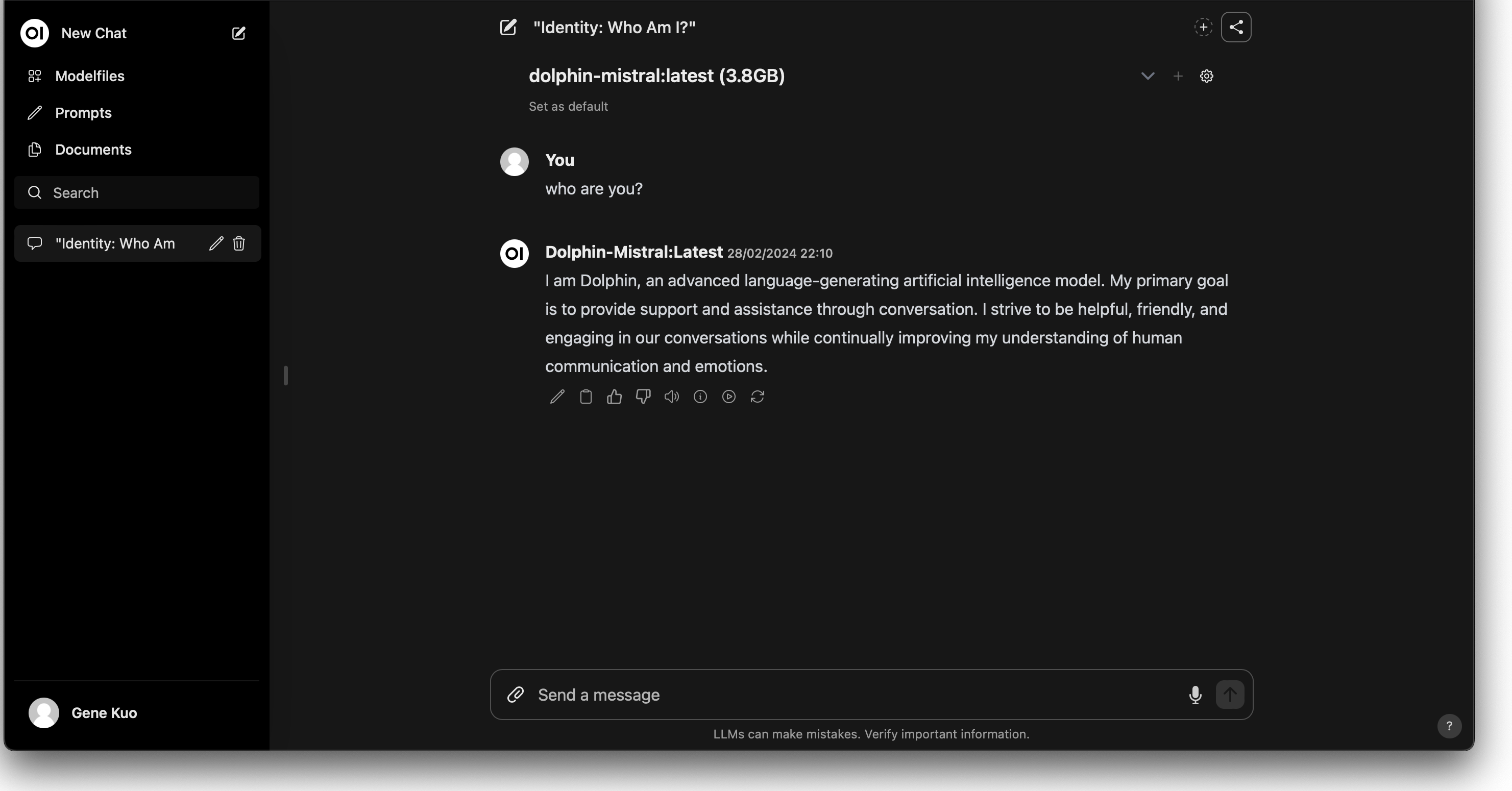
ダウンロード後、使用したいモデルを選択すれば、チャットボットとの対話を開始できます。
まとめ
以上の手順を通じて、Kubernetes環境でのNvidia GPUサポートのデプロイに成功しただけでなく、機能が充実したLLMチャットボットサイトを構築しました。これにより、KubernetesおよびNvidia GPUのデプロイに関する理解が深まっただけでなく、ハイパフォーマンスコンピューティング(HPC)アプリケーションやインタラクティブなAIサービスの構築に向けた実用的なリファレンスを提供することができました。

